条款01: parser
'''utils.py'''
def parse_command():
import argparse
parser = argparse.ArgumentParser(description='JAN')
parser.add_argument('--resume', default=None, type=str, metavar='PATH',
help='path to latest checkpoint (default: ./example.checkpoint.pth.tar')
parser.add_argument('--freeze', action='store_true', default=False,
help='freeze a module')
parser.add_argument('--batch-size', default=4, type=int,
help='mini-batch size (default: 4)')
parser.add_argument('--epochs', default=100, type=int, metavar='N',
help='number of total epoch to run (default: 100)')
parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float, metavar='LR',
help='initial learning rate (default: 1e-3)')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum (default: 0.9)')
parser.add_argument('--weight-decay', default=5e-4, type=float, metavar='W',
help='weight decay (default: 5e-4)')
parser.add_argument('--dataset', default='kitti', type=str,
help='dataset used for training, kitti and nyu is available')
parser.add_argument('--manual-seed', default=1, type=int,
help='manaully set random seed (default: 1)')
parser.add_argument('--gpu', default='0', type=str,
help='gpu id (default: '0')')
parser.add_argument('--print-freq', default=10, type=int, metavar='F',
help='print frequence (default: 10)')
args = parser.parse_args()
return args
条款02: output directory
'''utils.py'''
def get_output_directory(args):
save_dir_root = os.path.join(os.path.dirname(os.path.abspath(__file__)))
save_dir_root = os.path.join(save_dir_root, 'result', args.dataset)
if args.resume:
runs = sorted(glob.glob(os.path.join(save_dir_root, 'run_*')))
run_id = int(runs[-1].split('_')[-1]) if runs else 0
else:
runs = sorted(glob.glob(os.path.join(save_dir_root, 'run_*')))
run_id = int(runs[-1].split('_')[-1]) + 1 if runs else 0
save_dir = os.path.join(save_dir_root, 'run_' + str(run_id))
return save_dir
条款03: save checkpoint
'''utils.py'''
save_checkpoint({
'args': args,
'epoch': epoch,
'model': model.state_dict(),
'best_result': best_result,
'optimizer:' optimizer
}, is_best, epoch, output_directory)
import shutil
def save_checkpoint(state, is_best, epoch, output_directory):
checkpoint_filename = os.path.join(output_directory, 'checkpoint-' + str(epoch) + '.pth.tar')
torch.save(state, checkpoint_filename)
if is_best:
best_filename = os.path.join(output_directory, 'model_best.pth.tar')
shutil.copyfile(checkpoint_filename, best_filename)
条款04: color depth map
'''utils.py'''
import matplotlob.pyplot as plt
camp = plt.cm.jet
def color_depth_map(depth, d_min=None, d_max=None):
if d_min is None:
d_min = np.min(depth)
if d_max is None:
d_max = np.max(depth)
depth_relative = (depth - d_min) / (d_max - d_min)
return 255 * cmap(depth_relative)[:, :, :3]
条款05: save image
'''utils.py'''
def merge_into_row(input, depth_target, depth_pred):
rgb = 255 * np.transpose(np.squeeze(input.cpu().numpy()), (1, 2, 0)) # (H, W, C)
depth_target_cpu = np.squeeze(depth_target.cpu().numpy())
depth_pred_cpu = np.squeeze(depth_pred.cpu().numpy())
d_min = min(np.min(depth_target_cpu), np.min(depth_pred_cpu))
d_max = max(np.max(depth_target_cpu), np.max(depth_pred_cpu))
depth_target_col = color_depth_map(depth_target_cpu, d_min, d_max)
depth_pred_col = color_depth_map(depth_pred_cpu, d_min, d_max)
img_merge = np.hstack([rgb, depth_target_col, depth_pred_col])
return img_merge
def add_row(img_merge, row):
return np.vstack(img_merge, row)
from PIL import Image
def save_image(img_merge, filename):
img_merge = Image.fromarray(img_merge.astype('uint8'))
img_merge.save(filename)
# i: iteration
if i == 0:
img_merge = utils.merge_into_row(rgb, target, pred)
elif i < 8 * skip and (i % skip) == 0:
row = utils.merge_into_row(rgb, target, pred)
img_merge = utils.add_row(img_merge, row)
elif i == 8 * skip:
filename = os.path.join(output_directory, str(epoch) + '.png')
utils.save_image(img_merge, filename)
条款06: depth metircs
'''metrics.py'''
import math
import torch
import numpy as np
def log10(x):
return torch.log(x) / math.log(10)
class Result(object):
def __init__(self):
self.absrel, self.sqrel = 0., 0.
self.mse, self.rmse, self.mae = 0., 0., 0.
self.irmse, self.imae = 0., 0.
self.delta1, self.delta2, self.delta3 = 0., 0., 0.
# self.silog = 0.
self.data_time, self.net_time = 0., 0.
def set_to_worst(self):
self.absrel, self.sqrel = np.inf, np.inf
self.mse, self.rmse, self.mae = np.inf, np.inf, np.inf
self.irmse, self.imae = np.inf, np.inf
self.delta1, self.delta2, self.delta3 = 0., 0., 0.
# self.silog = np.inf
self.data_time, self.net_time = 0., 0.
def update(self, absrel, sqrel, mse, rmse, mae, irmse, imae, delta1, delta2, delta3, data_time, net_time):
self.absrel, self.sqrel = absrel, sqrel
self.mse, self.rmse, self.mae = mse, rmse, mae
self.irmse, self.imae = irmse, imae
self.delta1, self.delta2, self.delta3 = delta1, delta2, delta3
# self.silog = silog
self.data_time, self.net_time = data_time, net_time
def evaluate(self, output, target):
valid_mask = target > 0
output = output[valid_mask]
target = target[valid_mask]
abs_diff = (output - target).abs()
self.mse = float(abs_diff.pow(2).mean())
self.rmse = math.sqrt(self.mse)
self.mae = float(abs_diff.mean())
self.absrel = float((abs_diff / target).mean())
self.sqrel = float((abs_diff.pow(2) / target).mean())
inv_output = 1. / output
inv_target = 1. / target
abs_inv_diff = (inv_output - inv_target).abs()
self.irmse = math.sqrt(abs_inv_diff.pow(2).mean())
self.imae = float(abs_inv_diff.mean())
maxRatio = (output / target, target / output).max()
self.delta1 = float((maxRatio < 1.25).float().mean())
self.delta2 = float((maxRatio < 1.25 ** 2).float().mean())
self.delta3 = float((maxRatio < 1.25 ** 3).float().mean())
# log_diff = log10(output) - log10(target)
# self.silog = log_diff.pow(2).mean() - log_diff.sum().pow(2) / log_diff.numel().pow(2)
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.count = 0.
self.sum_absrel, self.sum_sqrel = 0., 0.
self.sum_mse, self.sum_rmse, self.sum_mae = 0., 0., 0.
self.sum_irmse, self.sum_imae = 0., 0.
self.sum_delta1, self.sum_delta2, self.sum_delta3 = 0., 0., 0.
self.sum_data_time, self.sum_net_time = 0., 0.
def update(self, result, data_time, gpu_time, n=1):
self.count += n
self.sum_absrel += n*result.absrel
self.sum_sqrel += n*result.sqrel
self.sum_mse += n*result.mse
self.sum_rmse += n*result.rmse
self.sum_mae += n*result.mae
self.sum_irmse += n*result.irmse
self.sum_imae += n*result.imae
self.sum_delta1 += n*result.delta1
self.sum_delta2 += n*result.delta2
self.sum_delta3 += n*result.delta3
self.sum_data_time += n*result.data_time
self.sum_net_time += n*result.net_time
def average(self):
avg = Result()
avg.update(
self.sum_absrel / self.count, self.sum_sqrel / self.count,
self.sum_mse / self.count, self.sum_rmse / self.count, self.sum_mae / self.count,
self.sum_irmse / self.count, self.sum_imae / self.count,
self.sum_delta1 / self.count, self.sum_delta2 / self.count, self.sum_delta3 / self.count,
self.sum_data_time / self.count, self.sum_net_time / self.count)
return avg
条款07: set random seed
'''main.py'''
import random
import numpy as np
torch.manual_seed(args.manual_seed)
torch.cuda.manual_seed(args.manual_seed)
np.random.seed(args.manual_seed)
random.seed(args.manual_seed)
条款08: resume
'''main.py'''
model = get_models(args.dataset, pretrained=True)
# you can use DataParallel() whether you use multi-gpus or not
model = nn.DataParallel(model).cuda()
train_params = [{'params': model.get_1x_lr_params, 'lr': args.learning_rate},
{'params': model.get_10x_lr_params, 'lr': args.learning_rate * 10}]
optimizer = torch.optim.SGD(train_params, lr=args.learning_rate, momentum=args.momentum, weight_decay=args.weight_decay)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=args.patience)
if args.resume:
assert os.path.isfile(args.resume), \
'=> No checkpoint found at {}'.format(args.resume)
print('Loading checkpoint {}'.format(args.resume))
checkpoint = torch.load(args.resume)
start_epoch = checkpoint['epoch'] + 1
best_result = checkpoint['best_result']
optimizer.load_state_dict(checkpoint['optimizer'])
model.load_state_dict(checkpoint['model'])
# clear memory
del checkpoint
# del model_dict
torch.cuda.empty_cache()
else:
start_epoch = 0
# ...
# scheduler.step(result.absrel)
条款09: config file
'''main.py'''
config_txt = os.path.join(output_directory, 'config.txt')
if not os.path.exists(config_txt):
with open(config_txt, 'w') as f_w:
args_ = vars(args)
args_str = ''
for k, v in args_.items():
args_str += str(k) + ':' + str(v) + ',\t\n'
f_w.write(args_str)
条款10: create log
'''main.py'''
import shutil
import socket
from datetime import datetime
from tensorboardX import SummaryWriter
log_path = os.path.join(output_directory, 'logs', datetime.now().strftime('%b%d_%H-%M-%S') + '_' + socket.gethostname())
if os.path.isdir(log_path):
shutil.rmtree(log_path)
os.makedirs(log_path)
logger = SummaryWriter(log_path)
# ...
# logger.close()
条款11: record the learning rate
'''main.py'''
for i, param_group in enumerate(optimizer.param_groups):
lr = float(param_group['lr'])
logger.add_scalar('LR/lr_' + str(i), lr, epoch)
条款12: best file
'''main.py'''
best_txt = os.path.join(output_directory, 'best.txt')
# define your best
is_best = result.rmse < best_result.rmse
if is_best:
best_result = result
with open(best_txt, 'w') as f_w:
f_w.write('epoch: {}, absrel: {:.3f}...'.format(epoch, best_result.absrel, ...))
if img_merge is not None:
img_filename = os.path.join(output_directory, 'best.png')
save_image(img_merge, img_filename)
条款13: record time
'''main.py'''
import time
start = time.time()
# load data
torch.cuda.synchronize()
data_time = time.time() - start
start = time.time()
# forward and backward
torch.cuda.synchronize()
gpu_time = time.time() - start
条款14: torch.autograd.detect_anomaly()
'''main.py train'''
with torch.autograd.detect_anomaly():
# forward
# backward
条款15: 1x and 10x
'''model'''
def get_1x_lr_params(self):
modules = [self.feature_extractor]
for m in modules:
for p in m.parameters():
if p.requires_grad:
yield p
def get_10x_lr_params(self):
modules = [self.aspp_module, self.orl]
for m in modules:
for p in m.parameters():
if p.requires_grad:
yield p
条款16: load state_dict except fc
'''model'''
def resnet101(pretrained=True):
resnet101 = ResNet(...)
if pretrained:
saved_state_dict = torch.load('...')
resnet101_state_dict = resnet101.state_dict().copy()
for i in saved_state_dict:
i_parts = i.split('.')
if not i_parts[0] == 'fc':
resnet101_state_dict['.'.join(i_parts)] = saved_state_dict[i]
resnet101.load_state_dict(resnet101_state_dict)
条款17: load state_dict from a to b
'''model'''
pretrained_dict = ...
model_dict = {}
state_dict = model.state_dict()
for k, v in pretrained_dict.items():
if k in state_dict:
model_dict[k] = v
state_dict.update(model_dict)
model.load_state_dict(state_dict)
条款18: initialize weight
'''model'''
def weights_init(m, type='xavier'):
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
if type == 'xavier':
torch.nn.init.xavier_normal_(m.weight)
elif type == 'kaiming':
torch.nn.init.kaiming_normal_(m.weight)
else:
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1.)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
if type == 'xavier':
torch.nn.init.xavier_normal_(m.weight)
elif type == 'kaiming':
torch.nn.init.kaiming_normal_(m.weight)
else:
m.weight.data.fill_(1.)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.Module):
for _m in m:
if isinstance(_m, nn.Conv2d) or isinstance(_m, nn.ConvTranspose2d):
if type == 'xavier':
torch.nn.init.xavier_normal_(_m.weight)
elif type == 'kaiming':
torch.nn.init.kaiming_normal_(_m.weight)
else:
n = _m.kernel_size[0] * _m.kernel_size[1] * _m.out_channels
_m.weight.data.normal_(0, math.sqrt(2. / n))
if _m.bias is not None:
_m.bias.data.zero_()
elif isinstance(_m, nn.BatchNorm2d):
_m.weight.data.fill_(1.)
_m.bias.data.zero_()
elif isinstance(_m, nn.Linear):
if type == 'xavier':
torch.nn.init.xavier_normal_(_m.weight)
elif type == 'kaiming':
torch.nn.init.kaiming_normal_(_m.weight)
else:
_m.weight.data.fill_(1.)
if _m.bias is not None:
_m.bias.data.zero_()
'''__init__'''
for m in self.modules():
if isinstance...
layers = [self.d0, ...]
for l in layers:
for m in l.modules():
if isinstance...
条款19: Full Image Encoder
'''model'''
class FullImageEncoder(nn.Module):
def __init__(self):
super(FullImageEncoder, self).__init__()
self.global_pooling = nn.AvgPool2d(16, stride=16, padding=(8, 8))
self.dropout = nn.Dropout(p=0.5)
self.global_fc = nn.Linear(2048 * 4 * 5, 512)
self.relu = nn.Relu(inplace=True)
self.conv = nn.Conv2d(512, 512, 1)
def forward(self, _input):
out = self.global_pooling(_input)
out = self.dropout(out)
out = out.view(-1, 2048 * 4 * 5)
out = self.relu(self.global_fc(out))
out = out.view(-1, 512, 1, 1)
out = self.conv(out)
out = F.interpolate(out, size=(49, 65), mode='bilinear')
return out
条款20: MSELoss L1Loss SmoothL1Loss ScaleInvariantLoss
SmoothL1Loss is a form of Huber Loss.
'''loss.py'''
import troch.nn.functional as F
class MaskedMSELoss(nn.Module):
def __init__(self):
super(MaskedMESLoss, self).__init__()
def forward(self, pred, target):
assert pred.dim == target.dim, 'MaskedMESLoss: inconsistent dimension'
valid_mask = (target > 0).detach()
diff = pred - target
diff = diff[valid_mask]
return (diff ** 2).mean()
class MaskedL1Loss(nn.Module):
def __init__(self):
super(MaskedL1Loss, self).__init__()
def forward(self, pred, target):
assert pred.dim == target.dim, 'MaskedL1Loss: inconsistent dimension'
valid_mask = (target > 0).detach()
diff = pred - target
diff = diff[valid_mask]
return diff.abs().mean()
class MaskedSmoothL1(nn.Module):
def __init__(self):
super(MaskedBerhuLoss, self).__init__()
def forward(self, pred, target):
assert pred.dim == target.dim, 'MaskedSmoothL1: inconsistent dimension'
valid_mask = (target > 0).detach()
loss = F.smooth_l1_loss(pred[valid_mask], target[valid_mask], reduction='none')
return loss.mean()
class ScaleInvariantLoss(nn.Module):
def __init__(self, _lambda):
super(ScaleInvariantLoss, self).__init__()
self._lambda = _lambda
def forward(self, pred, target):
pred_log = torch.log(pred)
target_log = torch.log(target)
diff_log = pred_log - target_log
return diff_log.pow(2).mean() - self._lambda * diff_log.mean().pow(2)
条款21: OrdLoss
'''loss.py'''
class OrdLoss(nn.Module):
def __init__(self):
super(OrdLoss, self).__init__()
def forward(self, pred, target):
"""
pred: N, K, H, W
target: N, 1, H, W
"""
N, C, H, W = pred.size()
ord_num = C
K = torch.arange(0, C, dtype=torch.int)
K = K.view(1, C, 1, 1).repeat((N, 1, H, W))
if torch.cuda.is_available():
K = K.cuda()
mask_0 = (K < target).detach()
mask_1 = (K >= target).detach()
one = torch.ones(pred[mask_1].size())
if torch.cuda.is_available():
one = one.cuda()
loss = torch.sum(torch.log(torch.clamp(pred[mask_0], min=1e-8, max=1e8))) +
torch.sum(torch.log(torch.clamp(one - pred[mask_1], min=1e-8, max=1e8)))
return loss / (-1 * N * H * W)
条款22: load rgb and depth
def rgb_read(filename, rgb=True):
# open path as file to avoid ResourceWarning and return it as a numpy array
with open(filename, 'rb') as f:
img = Image.open(f)
if rgb:
return np.array(img.convert('RGB'))
else:
return np.array(img.convert('I'))
def depth_read(filename):
# load depth map D from png file and return it as a numpy array
depth_png = np.array(Image.open(filename), dtype=int)
# make sure we have a proper 16bit depth map here.. not 8 bit
assert(np.max(depth_png) > 255)
depth = depth_png.astype(np.float32) / 256.
depth[depth_png == 0] = -1.
return depth
条款23: nconv
import torch
import torch.nn.functional as F
from torch.nn.modules.conv import _ConvNd
import numpy as np
from scipy.stats import poisson
from scipy import signal
class NConv2d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, pos_fn='softplus', init_method='k'):
super(NConv2d, self).__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, False, 0, groups, bias)
self.eps = 1e-20
self.pos_fn = pos_fn
self.init_method = init_method
self.init_parameters()
if pos_fn is not None:
EnforcePos.apply(self, 'weight', pos_fn)
def forward(self, data, conf):
# normalized convolution
demon = F.conv2d(conf, self.weight, None, self.stride, self.padding, self.dilation, self.groups)
nomin = F.conv2d(conf*data, self.weight, None, self.stride, self.padding, self.dilation, self.groups)
nconv = nomin / (demon + self.eps)
batch_size, out_channels, H, W = nconv.size()
_, in_channels, kernel_size, kernel_size = self.weight.size()
# add bias
bias = self.bias
bias = bias.view(1, out_channels, 1, 1)
bias = bias.expand_as(nconv)
nconv += bias
# propagate confidence
cout = demon
cout = cout.view(batch_size, out_channels, H * W)
weight = self.weight
weight = weight.view(out_channels, -1)
cout /= torch.sum(weight, dim=-1, keepdim=True)
cout = cout.view(batch_size, out_channels, H, W)
return nconv, cout
def init_parameters(self):
if self.init_method == 'x':
torch.nn.init.xavier_uniform_(self.weight)
elif self.init_method == 'k':
torch.nn.init.kaiming_uniform_(self.weight)
self.bias = torch.nn.Parameter(torch.zeros(self.out_channels) + 0.01)
class EnforcePos():
def __init__(self, pos_fn, name):
self.pos_fn = pos_fn
self.name = name
@staticmethod
def apply(module, name ,pos_fn):
fn = EnforcePos(pos_fn, name)
module.register_forward_pre_hook(fn)
return fn
def __call__(self, module, inputs):
if module.training:
weight = getattr(module, self.name)
weight.data = self._pos(weight).data
else:
pass
def _pos(self, p):
pos_fn = self.pos_fn.lower()
if pos_fn == 'softmax':
p_size = p.size()
p = p.view(p_size[0], p_size[1], -1)
p = F.softmax(p, dim=-1)
return p.view(p_size)
elif pos_fn == 'exp':
return torch.exp(p)
elif pos_fn == 'softplus':
return torch.softplus(p, beta=10)
elif pos_fn == 'sigmoid':
return troch.sigmoid(p)
else:
print('undefined positive function')
return
条款24: hourglass
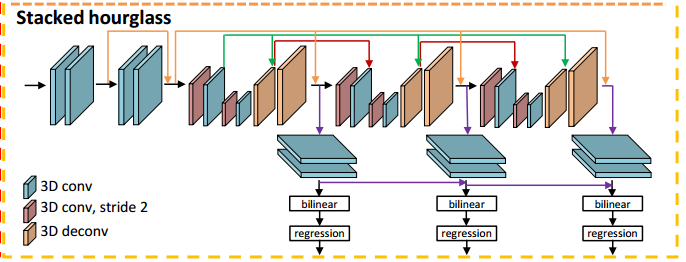
import torch.nn as nn
import torch.nn.functional as F
def convbn(in_channels, out_channels, kernel_size, stride, padding, dilation=1):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=dilation if dilation > 1 else padding, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels))
class hourglass(nn.Module):
def __init__(self, in_channels):
super(hourglass, self).__init__()
self.conv1 = nn.Sequential(convbn(in_channels, in_channels*2, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True))
self.conv2 = convbn(in_channels*2, in_channels*2, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Sequential(convbn(in_channels*2, in_channels*2, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True))
self.conv4 = nn.Sequential(convbn(in_channels*2, in_channels*2, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True))
self.conv5 = nn.Sequential(nn.ConvTranspose2d(in_channels*2, in_channels*2, kernel_size=3, stride=2, padding=1, output_padding=1, bias=False),
nn.BatchNorm2d(in_channels*2))
self.conv6 = nn.Sequential(nn.ConvTranspose2d(in_channels*2, in_channels, kernel_size=3, stride=2, padding=1, output_padding=1, bias=False),
nn.BatchNorm2d(in_channels))
def forward(self, x, presqu, postsqu):
out = self.conv1(x) # in: 1 out: 1/2
pre = self.conv2(out) # in: 1/2 out: 1/2
if postsqu is not None:
pre = F.relu(pre + postsqu, inplace=True)
else:
pre = F.relu(pre, inplace=True)
out = self.conv3(pre) # in: 1/2 out: 1/4
out = self.conv4(out) # in: 1/4 out: 1/4
post = self.conv5(out) # in: 1/4 out: 1/2
if presqu is not None:
post = F.relu(post + presqu, inplace=True)
else:
post = F.relu(post, inplace=True)
out = self.conv6(post) # in: 1/2 out: 1
return out, pre, post
条款25: 指定使用的GPU
'''
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' and
os.environ['CUDA_VISIBLE_DEVICES'] = 0,1 both ok
'''
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'